 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Phase-Aware Chunk Execution for Robot Policies with Action Chunking
May 30, 2026Recent vision-language-action and diffusion-based robot policies often use action chunking, where each policy query predicts a sequence of future actions and the robot executes an open-loop prefix before re-querying. While this interface improves local motion continuity, deployment still requires choosing the execution horizon: how much of each predicted chunk should be executed before acquiring a new observation. However, our experiments show that success is strongly task-dependent and non-monotonic with respect to the execution horizon, making a single constant horizon an unreliable deployment rule. We propose PACE (Phase-Aware Chunk Execution), a training-free test-time execution method that selects the execution horizon online from the predicted chunk itself. PACE exploits the phase-dependent kinematic structure of manipulation trajectories by identifying low-speed transition points in the predicted speed profile and using them as candidate replanning boundaries. Because PACE uses only the predicted action chunk, it is plug-and-play and requires no retraining or access to policy internals. We validate PACE through large-scale evaluations in both simulation and real-robot settings. On 50 RoboTwin2.0 tasks, PACE raises the average success rate from 57.8% to 64.2%. In real-robot experiments on bimanual ALOHA and single-arm Franka platforms, PACE improves the average task score from 60.7 to 77.7 and the average success rate from 50.7% to 70.4%. Ablations and rollout-level analyses show that PACE adapts execution horizons across manipulation phases, shortening near transitions while preserving longer execution during coherent motion.
VFEAgent: A Multimodal Agent Framework for End-to-End Automated Finite Element Analysis
May 27, 2026Finite Element Analysis (FEA) serves as the cornerstone of modern engineering design. However, its workflow is inherently complex and relies heavily on domain expertise. Although recent efforts have integrated Large Language Models (LLMs) into FEA, existing approaches face limitations in handling multimodal inputs and executing complex tasks. To address these limitations, we propose VFEAgent, an end-to-end multi-agent system designed to automate FEA modeling and simulation directly from input images and problem descriptions. Our methodology integrates two core components: (1) a multimodal vision-language multi-agent pipeline that employs ReAct-driven reasoning to extract structured FEA specifications from heterogeneous inputs and (2) a verification-first code synthesis framework, incorporating robust self-debugging and fallback mechanisms to ensure executability and physical validity. We systematically evaluated the system across various engineering mechanics scenarios. The results demonstrate that VFEAgent achieves a high success rate in generating complete and physically valid simulations, outperforming LLM-based baseline methods in reliability and correctness. These findings validate the feasibility of automating the complete FEA workflow, highlighting the framework's potential to liberate engineers from tedious manual analysis.
What Frozen VLAs Already Know About Success: A Probing Study of Value-Like Structure in Foundation Robot Policies
May 27, 2026Vision--language--action (VLA) policies are trained to imitate actions; their loss never asks them to estimate reward, progress, or future success. Their frozen representations nevertheless carry such information, and it can be read out and used to guide action choice without retraining the policy. From mixed successful and failed manipulation trajectories on LIBERO-Goal, we recover Monte-Carlo outcome targets using lightweight linear probes on frozen features. The targets are consistently predictable from OpenVLA, Pi0.5, DINOv2, and CLIP features, and substantially less so from baselines built on progress, time-to-go, task identity, or proprioception. To rule out task and temporal shortcuts, we evaluate the probes under same-task, same-timestep matched comparisons: Pi0.5 probes still reach roughly 92% pairwise ordering accuracy, while label-shuffled controls stay at chance. Used as a test-time selector over sampled Pi0.5 action prefixes, the same probe turns this offline finding into behavior: on push-plate, success rises from 26.7% under greedy decoding to 44.3%, with a second positive case on wine-rack. The gains are not universal and require additional inference compute, but the underlying finding is clean: frozen VLAs already encode information about success that their imitation objective never explicitly demands.
BifrostUMI: Bridging Robot-Free Demonstrations and Humanoid Whole-Body Manipulation
May 05, 2026High-quality data collection is a fundamental cornerstone for training humanoid whole-body visuomotor policies. Current data acquisition paradigms predominantly rely on robot teleoperation, which is often hindered by limited hardware accessibility and low operational efficiency. Inspired by the Universal Manipulation Interface (UMI), we propose BifrostUMI, a portable, efficient, and robot-free data collection framework tailored for humanoid robots. BifrostUMI leverages lightweight VR devices to capture human demonstrations as sparse keypoint trajectories while simultaneously recording wrist-mounted visual data. These multimodal data are subsequently utilized to train a high-level policy network that predicts future keypoint trajectories conditioned on the captured visual features. Through a robust keypoint retargeting pipeline, keypoint trajectories are precisely mapped onto the robot's morphology and executed via a whole-body controller. This approach enables the seamless transfer of diverse and agile behaviors from natural human demonstrations to humanoid embodiments. We demonstrate the efficacy and versatility of the proposed framework across two distinct experimental scenarios.
DIRCR: Dual-Inference Rule-Contrastive Reasoning for Solving RAVENs
Apr 19, 2026Abstract visual reasoning remains challenging as existing methods often prioritize either global context or local row-wise relations, failing to integrate both, and lack intermediate feature constraints, leading to incomplete rule capture and entangled representations. To address these issues, we propose the Dual-Inference Rule-Contrastive Reasoning (DIRCR) model. Its core component, the Dual-Inference Reasoning Module, combines a local path for row-wise analogical reasoning and a global path for holistic inference, integrated via a gated attention mechanism. Additionally, a Rule-Contrastive Learning Module introduces pseudo-labels to construct positive and negative rule samples, applying contrastive learning to enhance feature separability and promote abstract, transferable rule learning. Experimental results on three RAVEN datasets demonstrate that DIRCR significantly enhances reasoning robustness and generalization. Codes are available at https://github.com/csZack-Zhang/DIRCR.
OmniUMI: Towards Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction
Apr 12, 2026UMI-style interfaces enable scalable robot learning, but existing systems remain largely visuomotor, relying primarily on RGB observations and trajectory while providing only limited access to physical interaction signals. This becomes a fundamental limitation in contact-rich manipulation, where success depends on contact dynamics such as tactile interaction, internal grasping force, and external interaction wrench that are difficult to infer from vision alone. We present OmniUMI, a unified framework for physically grounded robot learning via human-aligned multimodal interaction. OmniUMI synchronously captures RGB, depth, trajectory, tactile sensing, internal grasping force, and external interaction wrench within a compact handheld system, while maintaining collection--deployment consistency through a shared embodiment design. To support human-aligned demonstration, OmniUMI provides dual-force feedback through bilateral gripper feedback and natural perception of external interaction wrench in the handheld embodiment. Built on this interface, we extend diffusion policy with visual, tactile, and force-related observations, and deploy the learned policy through impedance-based execution for unified regulation of motion and contact behavior. Experiments demonstrate reliable sensing and strong downstream performance on force-sensitive pick-and-place, interactive surface erasing, and tactile-informed selective release. Overall, OmniUMI combines physically grounded multimodal data acquisition with human-aligned interaction, providing a scalable foundation for learning contact-rich manipulation.
RPM-Net Reciprocal Point MLP Network for Unknown Network Security Threat Detection
Apr 08, 2026Effective detection of unknown network security threats in multi-class imbalanced environments is critical for maintaining cyberspace security. Current methods focus on learning class representations but face challenges with unknown threat detection, class imbalance, and lack of interpretability, limiting their practical use. To address this, we propose RPM-Net, a novel framework that introduces reciprocal point mechanism to learn "non-class" representations for each known attack category, coupled with adversarial margin constraints that provide geometric interpretability for unknown threat detection. RPM-Net++ further enhances performance through Fisher discriminant regularization. Experimental results show that RPM-Net achieves superior performance across multiple metrics including F1-score, AUROC, and AUPR-OUT, significantly outperforming existing methods and offering practical value for real-world network security applications. Our code is available at:https://github.com/chiachen-chang/RPM-Net
Low-Resource Crop Classification from Multi-Spectral Time Series Using Lossless Compressors
May 28, 2024



Deep learning has significantly improved the accuracy of crop classification using multispectral temporal data. However, these models have complex structures with numerous parameters, requiring large amounts of data and costly training. In low-resource situations with fewer labeled samples, deep learning models perform poorly due to insufficient data. Conversely, compressors are data-type agnostic, and non-parametric methods do not bring underlying assumptions. Inspired by this insight, we propose a non-training alternative to deep learning models, aiming to address these situations. Specifically, the Symbolic Representation Module is proposed to convert the reflectivity into symbolic representations. The symbolic representations are then cross-transformed in both the channel and time dimensions to generate symbolic embeddings. Next, the Multi-scale Normalised Compression Distance (MNCD) is designed to measure the correlation between any two symbolic embeddings. Finally, based on the MNCDs, high quality crop classification can be achieved using only a k-nearest-neighbor classifier kNN. The entire framework is ready-to-use and lightweight. Without any training, it outperformed, on average, 7 advanced deep learning models trained at scale on three benchmark datasets. It also outperforms more than half of these models in the few-shot setting with sparse crop labels. Therefore, the high performance and robustness of our non-training framework makes it truly applicable to real-world crop mapping. Codes are available at: https://github.com/qinfengsama/Compressor-Based-Crop-Mapping.
Point wise or Feature wise? Benchmark Comparison of Public Available LiDAR Odometry Algorithms in Urban Canyons
Apr 12, 2021
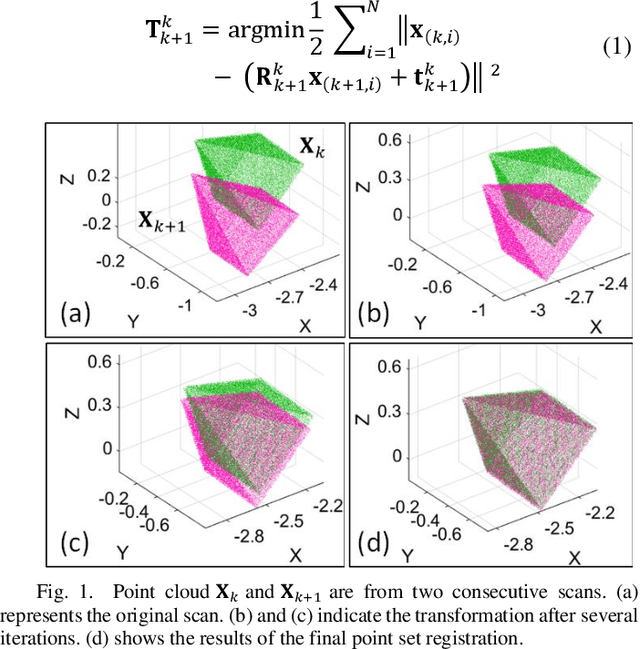

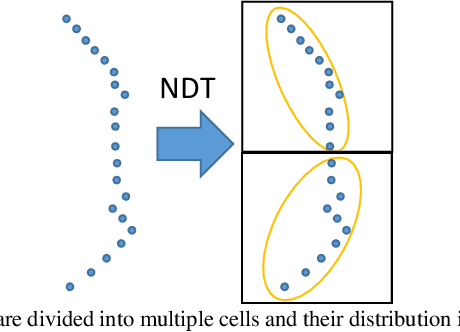
Robust and precise localization is essential for the autonomous system with navigation requirements. Light detection and ranging (LiDAR) odometry is extensively studied in the past decades to achieve this goal. Satisfactory accuracy can be achieved in scenarios with abundant environmental features using existing LiDAR odometry (LO) algorithms. Unfortunately, the performance of the LiDAR odometry is significantly degraded in urban canyons with numerous dynamic objects and complex environmental structures. Meanwhile, it is still not clear from the existing literature which LO algorithms perform well in such challenging environments. To fill this gap, this paper evaluates an array of popular and extensively studied LO pipelines using the datasets collected in urban canyons of Hong Kong. We present the results in terms of their positioning accuracy and computational efficiency. Three major factors dominating the performance of LO in urban canyons are concluded, including the ego-vehicle dynamic, moving objects, and degree of urbanization. According to our experiment results, point-wise achieves better accuracy in urban canyons while feature-wise achieves cost-efficiency and satisfactory positioning accuracy.